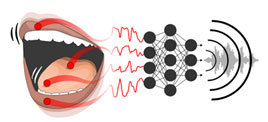
Il reconstitue la parole d’une personne articulant « silencieusement », sans vocaliser. Un algorithme d’apprentissage automatique, de type réseau de neurones profonds, décode les mouvements articulatoires grâce à des capteurs posés sur la langue, les lèvres et la mâchoire. Il les convertit en temps-réel en une parole de synthèse, sans restriction sur le vocabulaire. Le synthétiseur est a priori pilotable par n’importe quel locuteur, après une courte période de calibration. Les chercheurs travaillent actuellement sur une interface cerveau-machine dont l’objectif, à terme, est de reconstruire la parole en temps réel à partir de l’activité cérébrale.
Bibliographie :Real-Time Control of an Articulatory-Based Speech Synthesizer for Brain Computer Interfaces.
Florent Bocquelet, Thomas Hueber, Laurent Girin, Christophe Savariaux, Blaise Yvert.
PLOS
Computational Biology.http://dx.doi.org/10.1371/journal.pcbi.1005119Contact INSERM : Blaise Yvert
Contact CNRS : Thomas Hueber Légende de l'image :
Vue schématique du synthétiseur vocal pilotable en temps-réel, basé sur un algorithme d’apprentissage machine profond. © Bocquelet et al.